はじめに
このスクリプトは、指定したYouTubeチャンネルの最新動画URLと字幕テキストを自動で取得し、Googleスプレッドシートに書き込むものです。毎朝タスクスケジューラで自動実行することで、日経先物の最新動画情報を常に最新の状態に保つことができます。
全体の構成
スクリプトは大きく4つのブロックに分かれています。
- 設定 — ファイルパスやスプレッドシートIDなどの定数
- Google認証 — サービスアカウントでGoogleに接続する処理
- YouTube処理 — 動画URLと字幕を取得する処理
- メイン処理 — 上記を組み合わせて実行する処理
使用ライブラリ
import yt_dlp
import gspread
from google.oauth2.service_account import Credentials
| ライブラリ | 役割 |
|---|---|
yt_dlp | YouTubeの動画情報・字幕を取得する |
gspread | PythonからGoogleスプレッドシートを操作する |
google.oauth2.service_account | Googleサービスアカウントで認証する |
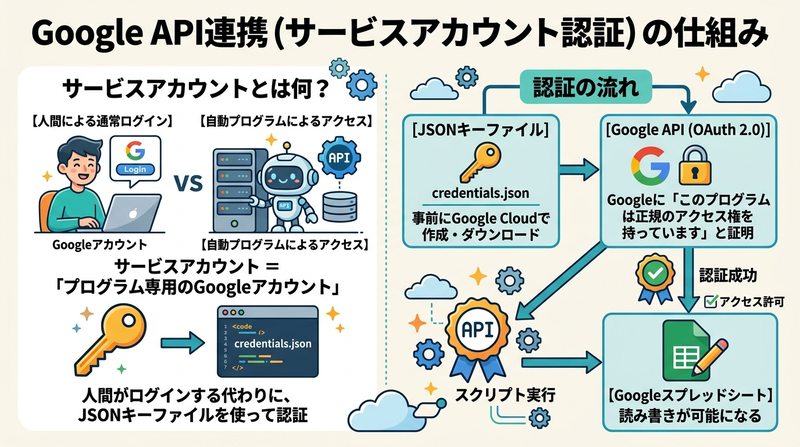
Google APIとの連携(サービスアカウント認証)
このスクリプトで最も重要な部分です。順を追って説明します。
サービスアカウントとは何か
通常、GoogleのサービスにアクセスするにはGoogleアカウントでログインします。しかし自動実行のプログラムは人間がログインできません。そこで使うのがサービスアカウントです。
サービスアカウントとは「プログラム専用のGoogleアカウント」のようなものです。人間がログインする代わりに、JSONキーファイルを使って認証します。
認証の流れ
credentials.json(JSONキーファイル)
↓
Googleに「このプログラムは正規のアクセス権を持っています」と証明
↓
Googleスプレッドシートへの読み書きが可能になる
credentials.jsonの中身
Google Cloud ConsoleでサービスアカウントのJSONキーをダウンロードすると、以下のような内容のファイルが手に入ります。
{
"type": "service_account",
"project_id": "your-project",
"private_key_id": "xxxx",
"private_key": "-----BEGIN RSA PRIVATE KEY-----\n...",
"client_email": "your-service@your-project.iam.gserviceaccount.com",
"client_id": "xxxx",
...
}
重要なのは client_email と private_key の2つです。Googleはこの秘密鍵を使って「本物のサービスアカウントからのリクエストかどうか」を検証します。
Pythonコードでの認証
from google.oauth2.service_account import Credentials
SCOPES = [
"https://www.googleapis.com/auth/spreadsheets",
"https://www.googleapis.com/auth/drive",
]
def get_worksheet():
creds = Credentials.from_service_account_file(
str(CREDENTIALS_FILE), scopes=SCOPES
)
gc = gspread.authorize(creds)
sh = gc.open_by_key(SPREADSHEET_ID)
return sh.sheet1
SCOPES(スコープ)について
スコープとは「このプログラムにどこまでのアクセスを許可するか」を定義するものです。
auth/spreadsheets— スプレッドシートの読み書きauth/drive— Googleドライブへのアクセス
必要最小限のスコープだけを指定するのがセキュリティ上の基本です。
Credentials.from_service_account_file()
credentials.jsonを読み込んでGoogleへの認証情報オブジェクトを作ります。このオブジェクトの中で秘密鍵を使った署名処理が行われ、Googleへのリクエスト時に「正規のアクセスである」ことを証明します。
gspread.authorize(creds)
gspreadライブラリに認証情報を渡して、Googleスプレッドシートを操作できるクライアントを作ります。
gc.open_by_key(SPREADSHEET_ID)
スプレッドシートのIDを指定してファイルを開きます。IDはスプレッドシートのURLの中にある長い文字列です。
https://docs.google.com/spreadsheets/d/【ここがID】/edit
スプレッドシートを共有する理由
サービスアカウントは「プログラム専用のGoogleアカウント」ですが、他のGoogleアカウントと同様、ファイルへのアクセス権が必要です。credentials.jsonの中の client_email(例:xxx@yyy.iam.gserviceaccount.com)に対してスプレッドシートを「編集者」として共有することで、スクリプトがそのファイルを読み書きできるようになります。
YouTube処理
最新動画URLの取得
def get_latest_video_url(channel_url: str) -> str:
base_url = channel_url.rstrip("/")
if not base_url.endswith("/videos"):
base_url += "/videos"
ydl_opts = {
"playlist_items": "1",
# 最新の1件だけ取得
"extract_flat": True,
# 動画情報のみ(ダウンロードしない)
"quiet": True,
"no_warnings": True,
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(base_url, download=False)
entries = info.get("entries", [])
video_id = entries[0]["id"]
return f"https://www.youtube.com/watch?v={video_id}"
yt_dlp はYouTubeの動画情報を取得するライブラリです。extract_flat: True にすることでダウンロードせずURLだけを取得できます。playlist_items: "1" で最新の1件に絞っています。
字幕テキストの取得
def get_transcript(video_url: str) -> str:
with tempfile.TemporaryDirectory() as tmpdir:
ydl_opts = {
"skip_download": True,
# 動画本体はダウンロードしない
"writeautomaticsub": True,
# 自動生成字幕を取得
"writesubtitles": True,
# 手動字幕を取得
"subtitleslangs": ["ja"],
# 日本語のみ
"subtitlesformat": "json3",
# JSON形式で保存
"outtmpl": os.path.join(tmpdir, "subtitle"),
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download([video_url])
files = glob.glob(os.path.join(tmpdir, "*.json3"))
with open(files[0], encoding="utf-8") as f:
data = json.load(f)
texts = []
for event in data.get("events", []):
for seg in event.get("segs", []):
t = seg.get("utf8", "").strip()
if t and t != "\n":
texts.append(t)
return " ".join(texts)
字幕は一時フォルダ(tempfile.TemporaryDirectory)にjson3形式でダウンロードし、テキストだけを抜き出して1つの文字列に結合します。一時フォルダは処理が終わると自動で削除されます。
スプレッドシートへの書き込み
def update_row(ws, row_index: int, last_url: str, content: str, updated_at: str):
ws.update(
range_name=f"C{row_index}:E{row_index}",
values=[[last_url, content, updated_at]],
)
ws.update() でC列からE列(last_url・content・updated_at)を一括で更新します。row_index は行番号で、ヘッダー行(1行目)を除いた2行目から順に処理します。
メイン処理の流れ
def main():
ws = get_worksheet()
# スプレッドシートに接続
channels = ws.get_all_records()
# 全チャンネル情報を取得
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
for i, channel in enumerate(channels, start=2):
c_url = channel.get("c_url", "")
last_url = get_latest_video_url(c_url)
# 最新動画URL取得
content = get_transcript(last_url)
# 字幕取得
update_row(ws, i, last_url, content, now)
# スプレッドシート更新
ws.get_all_records() でスプレッドシートの全行をPythonの辞書リストとして取得します。あとはチャンネルごとにループして、URL取得→字幕取得→書き込みを繰り返すだけです。enumerate(channels, start=2) の start=2 は1行目がヘッダーのため2行目から始めるためです。
まとめ:全体の処理の流れ
1. credentials.json を読み込んでGoogleに認証
2. スプレッドシートに接続してチャンネル一覧を取得
3. 各チャンネルについて:
├─ yt_dlp でチャンネルページの最新動画URLを取得
├─ yt_dlp で動画の日本語字幕をダウンロードしてテキスト化
└─ スプレッドシートのlast_url・content・updated_at列を更新
4. ログファイルに結果を記録
タスクスケジューラで毎朝このスクリプトを実行することで、スプレッドシートが常に最新の字幕テキストで更新されます。
WEBプログム、WEBデザインなどの制作については、以下を御覧ください。
WEBプログム、WEBデザインなどの制作